

RelationPrompt: Leveraging Prompts for Zero-Shot Relation Triplet Extraction
How to generate free data for zero-shot learning.


Introduction
Knowledge bases are large-scale data structures that store the relationships between entities and underpin many knowledge-related applications, such as search engines, question answering, and fact-checking. However, knowledge bases are challenging to construct as they are composed of relation triplets that need to be extracted from various sources such as text articles. An example of a relation triplet is (United States, has president, Joe Biden). Although existing models for natural language processing can perform the relation triplet extraction task, they are brittle and cannot generalize well to new relationships. Hence, we introduce a new benchmark called Zero-Shot Relation Triplet Extraction (ZeroRTE) which requires models to extract relation triplets for previously unseen relation types. In other words, the model is required to perform zero-shot learning, as it has exactly zero training examples for the unseen relations. Due to the challenge of the task, we propose a radically new approach called RelationPrompt. We use language models to generate synthetic training examples for the desired relations and simply train a second model on the synthetic data to perform the extraction task. Hence, we show that language models are able to generate diverse and high-quality training examples, overcoming the zero-shot learning challenge.
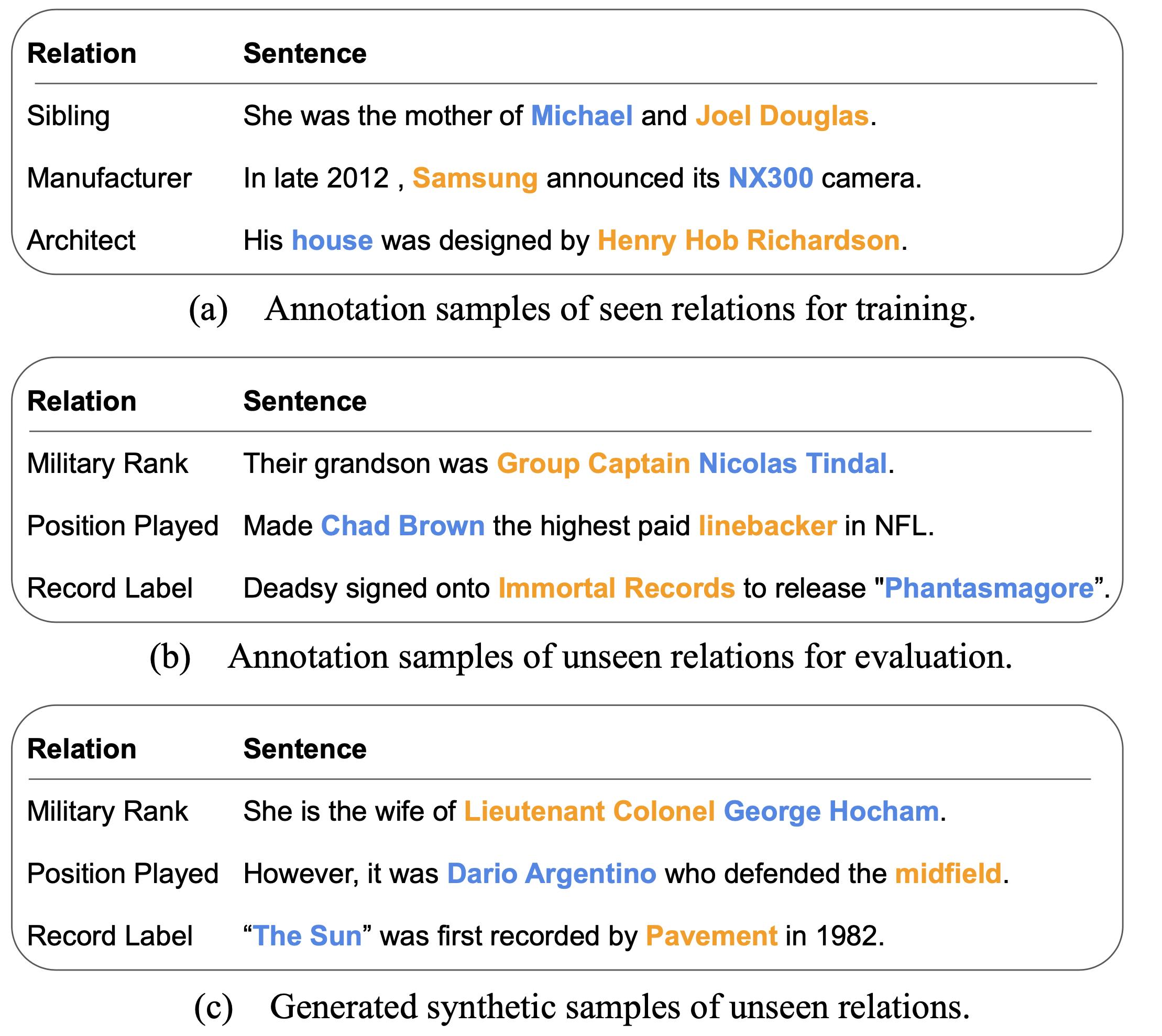
The diagram above shows our proposed task of ZeroRTE. The model learns to extract relation triplets such as (Michael, Sibling, Joel Douglas) from the training data (a). Thereafter, it is required to generalize to the testing data (b) which contains a totally different set of relations and extract triplets such as (Nicolas Tindal, Military Rank, Group Captain). In order to solve the zero-shot learning challenge, we propose to generate synthetic samples (c) such as (George Hocham, Military Rank, Lieutenant Colonel).
Approach

To generate the synthetic samples, we leverage and fine-tune pre-trained language models with prompts, hence the name RelationPrompt. Language models are widely known to generate realistic and high-quality texts after learning useful language representations from their large-scale pre-training corpus. The generated outputs of language models can be easily controlled by varying the starting prompt, and recent research has shown the effectiveness of prompts for performing a wide variety of tasks with little to no training data. Hence, the diagram above shows our prompt-based approach for text generation. The model input contains the relation label which we use to condition the language model. The model output first contains the generated sentence, and then the entity pair which demonstrates the relationship in the sentence. In order words, the generated output contains the full information needed to train a model for relation triplet extraction.
Results
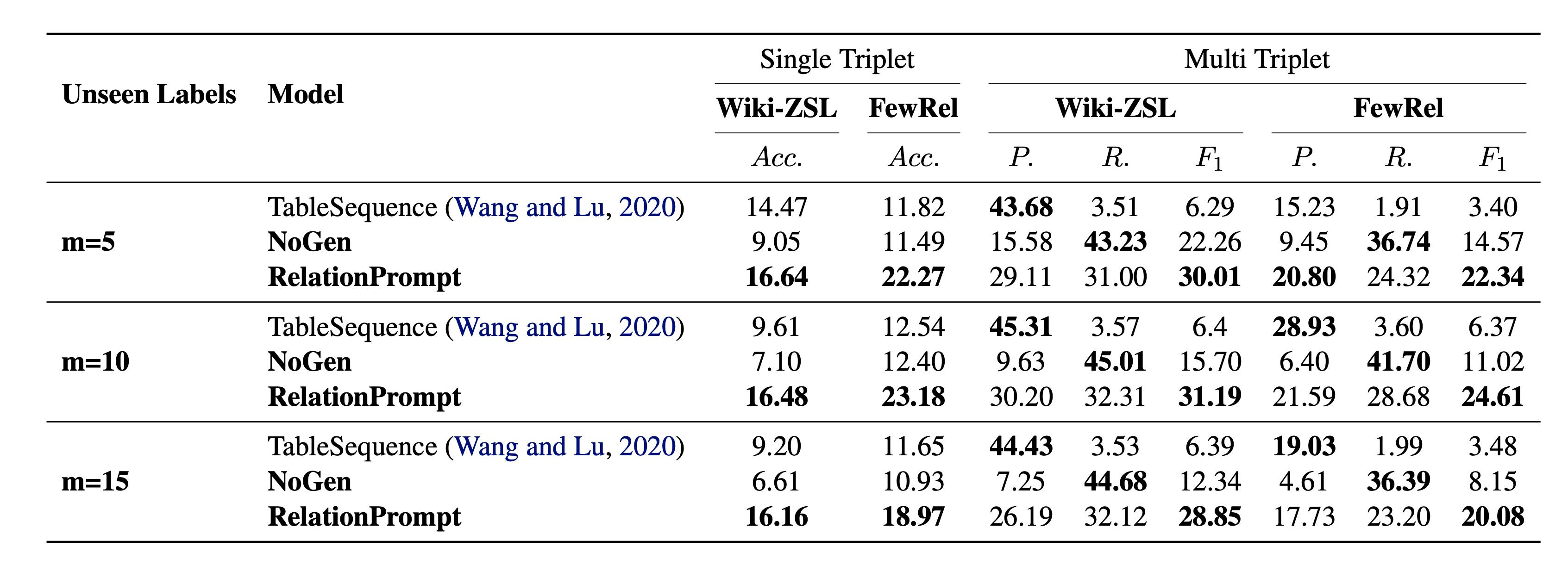
To evaluate the effectiveness of our approach, we run a comparison with baselines on two public datasets. As shown in the table above, RelationPrompt consistently outperforms the baseline methods on all settings. Although there is still much room for improvement, we show that it is indeed possible to perform the task of extracting relation triplets in a zero-shot setting.
Analysis

We further provide a case study to show how RelationPrompt generalizes to relations found in the wild. In the diagram above, the samples on the left are real sentences collected from web articles. On the right, we present synthetic sentences generated by RelationPrompt. In most cases, the generator is able to determine the correct meaning of the relations and compose reasonable sentences. However, in the last case for the relation of “Political Partner”, the generated entity pair is not quite suitable, and instead expresses a relationship that is closer to “Political Party”. This suggests that future work can focus on enforcing the consistency between the prompted relation meaning and generated output.
Conclusion
In this work, we introduce the task setting of Zero-Shot Relation Triplet Extraction (ZeroRTE) to pave the way for natural language processing models to generalize to new relation types. To solve ZeroRTE, we propose an approach called RelationPrompt and show that language models can effectively generate synthetic training data. The synthetic data generated from prompts is diverse and realistic. The experimental results show that our method significantly outperforms baselines, setting the bar for future work.